TL;DR. Recently, lowRISC published the design rationale of the post-quantum cryptography hardware extensions for future OpenTitan versions, leaving open the questions on how these hardware extensions can be sensibly leveraged in a hardware/software co-design of a PQC algorithm. In this article, we explain how the trifecta of engineering prowess, cutting-edge research and cryptographic know-how paved the way towards a FIPS-compliant implementation of the ML-DSA digital signature scheme that is side-channel-hardened without compromising efficiency both in running time and memory utilization. The result is a complete first-order side-channel-hardened software implementation of ML-DSA, including a formally verified masking accelerator which fits in 16 KiB of instruction memory, 32 KiB of data memory, computes a signature verification in roughly 300000 clock cycles and completes one signature generation rejection loop in about 800000 cycles1. The code is available in the OpenTitan upstream repository.
Background
The NIST post-quantum standardization process produced cryptosystems that are complex and whose implementation choices are open to interpretation. It is the task of the rational engineer to establish a set of ground truths from which a priori and a posteriori knowledge are drawn and which ultimately illuminate the path towards a sensible implementation. In our context, a priori knowledge refers to known things which are not empirically backed, dogmas and axioms that can be transformed into a posteriori knowledge through measurements and experiments.
A priori
Let us conduct this exercise for the lattice-based digital signature scheme ML-DSA-87 (the largest variant) and gather all the a priori knowledge for our implementation in OpenTitan2.
OTBN. Cryptographic algorithms in OpenTitan are either provided as hardware IP blocks as is the case for AES and SHA or implemented in the OpenTitan Big Number accelerator (OTBN) which is a standalone RV32-like co-processor that supports 256-bit wide arithmetic instructions that are useful for public-key cryptosystems like ECDSA and RSA3. Our ML-DSA implementation follows the same path as the former and is entirely implemented in OTBN.
Vectorization. The base data structure of ML-DSA is the integer polynomial whose coefficients, for the most part, can be processed independently. This renders the algorithm “embarrassingly” parallel in the presence of Single-Instruction-Multiple-Data-style (SIMD) arithmetic instructions. We assume the presence of 8×32-bit SIMD instructions to process eight polynomial coefficients within one 256-bit register in parallel.
KMAC Interface. ML-DSA is a sample-heavy algorithm that derives most of its polynomial data structures by sampling bytes from the SHAKE XOF, a SHA-derived Extendible Output Function. In OpenTitan, a hardened SHAKE implementation is provided by the KMAC (Keccak Message Authentication Code) hardware IP block which we assume interfaces directly with the OTBN for easy extraction of sampled bytes.
Masking Accelerator Interface. Our ML-DSA implementation is side-channel-hardened which means that sensitive values remain masked in two shares throughout all computations. To achieve this efficiently we assume that widely used transformations to handle different masked representations (boolean and arithmetic) are provided by a dedicated vectorized masking accelerator interface. The basic functions provided by the masking accelerator interface are both necessary and sufficient to implement virtually every known masked operation and we have verified the SCA hardening of these basic functions at the netlist level using formal masking verification and simulation-based SCA leakage assessments (link). The question then remains how efficiently lattices can be masked. Usually masking an algorithm means that operations handling sensitive values are either calculated twice or are replaced by dedicated masked gadgets that are built upon some cardinal operations (as provided by our masking accelerator interface). A gadget is a software function that takes masked values as an input and computes a function over them without revealing any information about the secret unmasked input values. For example, gadgets in ML-DSA allow securely sample masked polynomial coefficients or compare them against bounds without unmasking. Either way, side-channel-hardening an algorithm incurs an overhead in all important metrics (running time, memory utilization, circuitry), the challenge lies in keeping this overhead minimal.
For a detailed overview of all the aforementioned points, the reader is referred to the original design rationale4.
Transformations
The task now lies in extrapolating the facts from the previous section and map the a priori knowledge into measurable a posteriori truths.
- Assembler: We show how our ML-DSA code demarcates itself in structure and organization from existing algorithms in the OpenTitan cryptography library.
- Streaming/memory reuse: We show how aggressively streaming most of the intermediate results and reutilizing stale memory makes the algorithm fit in only 32 KiB of data memory.
- Parallelism: We show how we leverage the inherent parallelism of lattice arithmetic to reduce the running time.
- Efficient sampling: We show how we optimize the various polynomial sampling routines to further reduce the number of clock cycles.
- Efficient masking: We show how we implement an efficient first-order order masking.
Assembler. OTBN implementations are handwritten assembly programs that can quickly grow into intricate applications that comprise thousands of instructions. Unlike previous OTBN cryptography code that followed a different approach to program structure and register allocation, ML-DSA is designed in a bottom-up fashion by first allocating and assigning stretches of 32-bit and 256-bit registers to certain parts of the algorithm and then preventing routines from modifying the registers of their parent routines. These two measures provide a light form of program encapsulation that mimics the function call paradigm of higher-level languages5.
Streaming. One remedy to limit the data memory usage lies in streaming or generating intermediate values on-the-fly when they are needed. With the exception of keys, all the polynomial vectors and matrices in ML-DSA are either directly sampled from the XOF or are results of polynomial arithmetic between two existing polynomials. This means that at most two polynomials need to reside in memory in their complete representation at any point in time. This was first pointed out by Bos, Renes and Sprenkels6, strictly following their approach would result in an unsuitably slow but very memory-efficient ML-DSA implementation. However we found an appropriate middle ground between allocating memory for intermediate values and streaming them to arrive at a program that is sufficiently fast but does not consume too much memory in the process7.
Memory reuse. In the same vein as streaming, memory space is gained by sensibly reordering operations and reusing memory of stale variables. As with every moderately complex algorithm, this eventually boils down to traversing the program flow graph for potential optimizations. Again, it is in the work by Bos, Renes and Sprenkels where we can find the most recent variable reuse strategy for the goal of improving the ML-DSA data memory usage.
Parallelism. Polynomials are traversed in chunks of eight coefficients where possible, which in turn means that all operations within those iterations are fully parallelized through the usage of the SIMD instructions. This includes all the polynomial arithmetic (addition, subtraction, multiplication), complex transformations like the number-theoretic transform (NTT), sampling routines to sample polynomial coefficients in various intervals and encoding/decoding procedures to switch polynomials between dense and canonical representations.
Efficient sampling. Most of the computing time in any ML-DSA implementation is spent sampling polynomial coefficients. Several tens of thousands of bytes are squeezed from the XOF in a single invocation of the key/sign generation or signature verification. Assuming that the KMAC interface is implemented in a concise manner, such that squeezed bytes are seamlessly transferred from the KMAC block to the registers inside the OTBN with small latency, the remaining optimizations can take place in the sampling algorithms themselves specifically the handling of rejections of invalid coefficients. In cases where the rejections occur only sporadically it is sensible to first fully sample all the coefficients of a polynomial without any rejections then in a second pass discard invalid coefficients. This technique is immediately obvious for the case of the sampling of the lattice matrix whose coefficients are sampled with a very high success rate, meaning that a polynomial is sampled without the need for correction with high probability thus offsetting the overhead of the correction step.
Efficient masking. Masking ML-DSA is an ongoing and active research topic that is bound to evolve in the coming months and years. The current gold standard is the work by Azouaoui et al.8 that contains the most up-to-date sensitivity analysis of the signature scheme and proposes new efficient gadgets for the computation of certain operations over masked data. Once again, we assume that a concise interface is provided that allows the efficient processing of masked polynomials in a SIMD fashion, i.e., eight coefficients at a time. The implementation of the gadgets is then guided and informed by the OTBN secure coding guidelines9 which were established through the rigorous formal verification and penetration testing of the first production OpenTitan silicon. This created an indispensable feedback loop that ultimately led to a securely masked ML-DSA algorithm that withstands future evaluations both formal and practical10. It is to be noted that the paper by Azouaoui et al. does not provide a FIPS-compliant sampling gadget to sample the coefficients of the secret key polynomials, we therefore researched and designed our own gadget for that purpose.
A posteriori
Now that the transformations are in place and the fully SCA hardened algorithm is implemented11, we can now conduct the experiments to assess their effectiveness. We are looking at three metrics, instruction/data memory (IMEM/DMEM) utilization and running time (measured by the number of clock cycles).
IMEM. An OTBN program needs to be small enough12 (measured by its number of individual instructions) that it can be assembled as a single binary blob to be fully loaded into the instruction memory. In the first version of OpenTitan Earl Grey, the IMEM had a size of 8 KiB (8192 bytes) which was subsequently increased to 16 KiB for future versions, which appears to be plenty for ML-DSA as demonstrated by our implementation.

Compared to the largest existing OTBN algorithm (ECDSA over the P-384 curve), the ML-DSA-87 program is, as expected, significantly larger since the implementation of only a single function (keygen, sign, verify) is roughly the same size as the full ECDSA suite. Nonetheless, the existence of vectorized arithmetic instructions in combination with efficient interfacing to the KMAC and masking circuits guarantees that the IMEM figures remain well below the 16 KiB limit with ample space for future extensions of the code.13
DMEM. The ML-DSA key generation, sign and verify functions have distinct memory layouts pertaining to the differences in the algorithms. The size of the verify function is less of a concern as all of its data is considered public, hence for this function the available data memory (32 KiB increased from 4 KiB in the first version of Earl Grey) should be utilized to optimize the running time of the function. Signatures are more often verified than generated which means that the verification function appears on the critical path of protocols, such as secure boot, and should therefore be as quick as possible. Key generation and signature generation functions, on the other hand, operate with secret data structures that are masked in two shares (twice the size compared to unshared data). The optimization aspect for these two functions lies thus less on the running time (although it must not be too slow) but more on making the masked functions fit into the available space, i.e., 32 KiB.
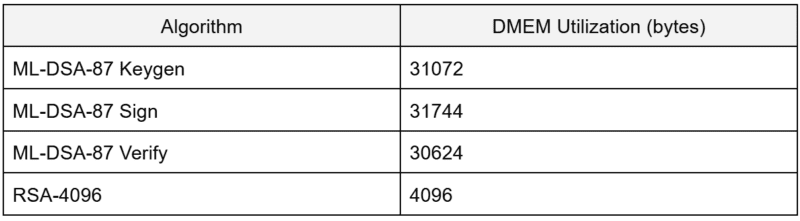
For each of the three ML-DSA functions, the DMEM layout is below the maximum of 32 KiB, which leaves further room for future amendments. The DMEM utilization is an order of magnitude larger than for the previous largest algorithm RSA-4096.
Running time. With the assembly and the data memory layout fixed, all that is left to do is to measure the actual time it takes to compute a key generation, a signature and a verification. This is a rather straightforward task for key generation and verification as their internal sampling routines only exhibit small variance. Signing employs a rejection loop that generates signatures until it finds a valid one. On average this loop iterates ~4 times for ML-DSA-87 hence the running time for the signature generation function can only be given as an average over many tries.
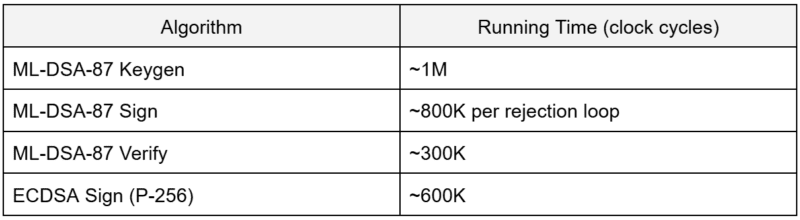
Our ML-DSA implementation compares favourably to existing algorithms benefiting from the SIMD instruction set extension and the KMAC/masking interfaces.
Future
The ML-DSA implementation is complete in the sense that it is masked and computes what it ought to, i.e., it conforms with the FIPS-204 specification. Still, there remain some open avenues to explore in future work.
Fault-injection hardening. The program in its current form is not yet hardened against fault injection attacks. This is a delicate undertaking for ML-DSA whose FI-hardening has only seen little treatment in research so far. This stands in contrast to its PQC encryption counterpart ML-KEM whose body of FI countermeasures is more pronounced. Fault-injection countermeasures for digital signature schemes usually fall into two groups: Coarse-grained countermeasures attempt to provide some redundancy by treating the algorithm as a black box. Common examples include computing a signature verification after the signature generation or simply computing a function twice. Fine-grained countermeasures secure individual sub-functions of an algorithm. Examples are integrity checks on sensible values or shuffling the execution order of operations. We are confident that some combination of coarse-grained and fine-grained countermeasures will be sufficient to adequately protect ML-DSA against fault-injection attacks.
Improved masking gadgets. Our masking approach is only a snapshot of the current state of research that is bound to evolve. Newer gadgets might appear, existing ones revised or discarded. However, since all our gadgets are software implementations that use the masking accelerator for core functionality, and the masking accelerator itself is a set of general and well-established circuits that are formally verified, any changes to the existing gadgets will be a straightforward task.
Complete security evaluation. The masking accelerator is formally verified, which is the most crucial milestone in the eventual evaluation of the complete algorithm. The remaining task is the measurement of the algorithm (including individual gadgets) on an FPGA, as has already been done for other primitives in the OpenTitan cryptographic library, to empirically rule out any leakage.
Conclusion
In this article, we have outlined the path taken for implementing our side-channel hardened ML-DSA implementation fully leveraging the extended hardware capabilities of the second-generation of the OpenTitan design. In a nutshell, our key ingredients are:
- a bottom-up software implementation approach for efficient register allocation,
- a balanced streaming implementation including the reordering of operations to hit a sweet spot between hardening and performance without requiring more than 32 KiB of data memory and 16 KiB of instruction memory,
- SIMD parallelism,
- efficient KMAC output sampling, and
- an efficient masking scheme leveraging existing research, experience from previous pentesting campaigns, a generic but formally verified hardware accelerator for the most critical but well-established mask conversion operations, as well as our own expertise to close the remaining research gaps to come up with a hardened implementation that is also FIPS compliant.
Our open-source ML-DSA implementation is now available as part of the upstream OpenTitan repository. It is the first open-source implementation of a post-quantum algorithm whose first-order SCA security is based on formally verified masking hardware. Our work provides proof that a sensible hardware-software co-design based on the latest research is the right approach for accelerating and masking lattice-based algorithms not only in the context of OpenTitan but more generally for other resource-constrained environments. The resulting implementation is fast, small and secure, which are all the attributes required for securing digital systems ranging from embedded hardware to server SoCs against quantum attacks.
Get Involved
The OpenTitan project is stewarded by lowRISC C.I.C. a not-for-profit engineering company that creates and maintains commercial-grade open source silicon designs through its collaborative Silicon Commons® approach. As the post-quantum world comes ever closer the OpenTitan partnership and lowRISC are committed to a roadmap that addresses these challenges head on.
If you would like to find out more about OpenTitan and its approach to PQC then contact us at get-involved@opentitan.org
- 300000 clock cycles at a clock frequency of 200 MHz results in a latency of 1.5 ms.
- Truthfully, this work has already been performed as ML-DSA is fully implemented. This is a mere retelling.
- SLH-DSA in OpenTitan is an exception to this rule as it is implemented on the Ibex core.
- https://lowrisc.org/news/opentitan-big-number-otbn-accelerator-hardware-extensions-for-post-quantum-cryptography-extended-design-rationale
- Registers that are modified by a routine are consequently saved in memory at the beginning and restored upon returning to the parent routine.
- https://doi.org/10.1007/978-3-031-17433-9_10
- On-the-fly encoding/decoding works in the same way and can lead to even more memory reductions. For instance, a polynomial of the secret/public key can be kept in a dense (encoded) representation until it is needed in a calculation when it is decoded to the canonical (decoded) representation.
- https://doi.org/10.46586/tches.v2023.i4.58-79
- https://opentitan.org/book/doc/contributing/style_guides/otbn_style_guide.html?highlight=secure%20coding#secure-coding-for-cryptography
- Importantly, our masking approach is a conservative one that aims at protecting all the sensitive operations from adversarial side-channel measurements. We believe that this stringent technique is essential for achieving Common Criteria certification.
- https://github.com/lowRISC/opentitan/tree/master/sw/otbn/crypto/mldsa87
- Every OTBN instruction, whether it be RV32 or big-number, is four bytes (32 bits) wide.
- Executing 8 32-bit arithmetic operations in parallel is a single instruction. Writing and reading data from the XOF and accessing the masking interface is also achieved through single-instruction operations.